

Python 中的数据库访问
Python 中的数据库访问用于与数据库交互,使应用程序能够一致地存储、检索、更新和管理数据。这些任务支持各种关系数据库管理系统 (RDBMS),每个系统都需要特定的 Python 包进行连接 -
- GadFly
- MySQL
- PostgreSQL
- Microsoft SQL Server
- Informix
- Oracle
- Sybase
- SQLite
- and many more...
程序执行期间输入和生成的数据存储在 RAM 中。如果要持久化存储,则需要将其存储在数据库表中。
关系数据库使用 SQL(结构化查询语言)对数据库表执行 INSERT/DELETE/UPDATE 操作。但是,SQL 的实现因数据库类型而异。这会引发不兼容问题。一个数据库的 SQL 指令与其他数据库不匹配。
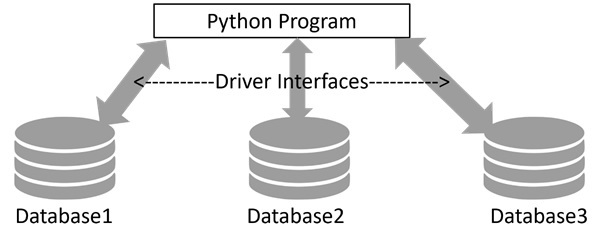
DB-API(数据库 API)
为了解决这个兼容性问题,Python 增强提案 (PEP) 249 引入了一个称为 DB-API 的标准化接口。此接口为数据库驱动程序提供了一致的框架,确保不同数据库系统之间的统一行为。它通过建立一组通用的规则和方法简化了在各种数据库之间转换的过程。
将 SQLite 与 Python 结合使用
Python 的标准库包括 sqlite3 模块,这是一个 SQLite3 数据库的 DB_API 兼容驱动程序。它用作 DB-API 的参考实现。对于其他类型的数据库,您必须安装相关的 Python 软件包 -
| 数据库 | Python 软件包 |
|---|---|
| Oracle | cx_oracle, pyodbc |
| SQL Server | pymssql, pyodbc |
| PostgreSQL | psycopg2 |
| MySQL | MySQL Connector/Python, pymysql |
使用 SQLite
由于内置了 sqlite3 模块,将 SQLite 与 Python 一起使用非常容易。该过程包括 -
- 连接建立 - 使用 sqlite3.connect() 创建连接对象,提供必要的连接凭据,例如服务器名称、端口、用户名和密码。
- 事务管理 - 连接对象管理数据库操作,包括打开、关闭和事务控制(提交或回滚事务)。
- 光标对象 − 从连接中获取游标对象以执行 SQL 查询。游标用作对数据库执行 CRUD (Create, Read, Update, Delete) 操作的网关。
在本教程中,我们将学习如何使用 Python 访问数据库,如何在 SQLite 数据库中存储 Python 对象的数据,以及如何从 SQLite 数据库中检索数据并使用 Python 程序对其进行处理。
sqlite3 模块
SQLite 是一种无服务器、基于文件的轻量级事务关系数据库。它不需要任何安装,也不需要用户名和密码等凭据即可访问数据库。
Python 的 sqlite3 模块包含 SQLite 数据库的 DB-API 实现。它由 Gerhard Häring 编写。让我们学习如何使用 sqlite3 模块通过 Python 访问数据库。
让我们从导入 sqlite3 开始并检查其版本。
Connection 对象
连接对象由 sqlite3 模块中的 connect() 函数设置。此函数的第一个位置参数是一个字符串,表示 SQLite 数据库文件的路径(相对或绝对)。该函数返回引用数据库的连接对象。
在 connection class 中定义了各种方法。其中之一是 cursor() 方法,它返回一个光标对象,我们将在下一节中了解。事务控制是通过连接对象的 commit() 和 rollback() 方法实现的。Connection 类具有定义要在 SQL 查询中使用的自定义函数和聚合的重要方法。
Cursor 对象
接下来,我们需要从 connection 对象中获取 cursor 对象。它是在数据库上执行任何 CRUD 操作时对数据库的句柄。connection 对象上的 cursor() 方法返回 cursor 对象。
我们现在可以借助光标对象可用的 execute() 方法执行所有 SQL 查询操作。此方法需要一个字符串参数,该参数必须是有效的 SQL 语句。
创建数据库表
现在,我们将在新创建的 'testdb.sqlite3' 数据库中添加 Employee 表。在下面的脚本中,我们调用游标对象的 execute() 方法,给它一个里面有 CREATE TABLE 语句的字符串。
当运行上述程序时,将在当前工作目录中创建带有 Employee 表的数据库。
我们可以通过在 SQLite 控制台中列出此数据库中的表来验证。
INSERT 操作
当您要将记录创建到数据库表中时,需要 INSERT 操作。
例以下示例执行 SQL INSERT 语句以在 EMPLOYEE 表中创建记录 -
您还可以使用参数替换技术执行 INSERT 查询,如下所示 -
READ 操作
对任何数据库的 READ 操作都意味着从数据库中获取一些有用的信息。
建立数据库连接后,您就可以对此数据库进行查询了。您可以使用 fetchone() 方法获取单个记录,或使用 fetchall() 方法从数据库表中获取多个值。
- fetchone() − 它获取查询结果集的下一行。结果集是使用游标对象查询表时返回的对象。
- fetchall() − 它获取结果集中的所有行。如果某些行已经 从结果集中提取,然后从结果集中检索其余行。
- rowcount - 这是一个只读属性,并返回 受 execute() 方法影响。
在下面的代码中,游标对象执行 SELECT * FROM EMPLOYEE 查询。结果集是使用 fetchall() 方法获取的。我们使用 for 循环打印 resultset 中的所有记录。
它将产生以下输出 -
fname=Makrand,lname=Mohan,age=21,sex=M,income=5000.0
Update 操作
Update 对任何数据库的操作意味着更新数据库中已有的一条或多条记录。
以下过程将更新所有具有 income=2000 的记录。在这里,我们将收入增加了 1000。
DELETE 操作
当您要从数据库中删除某些记录时,需要执行 DELETE 操作。以下是从 EMPLOYEE 中删除 INCOME 小于 2000 的所有记录的过程。
执行事务
事务是确保数据一致性的一种机制。交易具有以下四个属性 -
- 原子性 − 事务完成或根本没有发生任何事情。
- 一致性 - 事务必须以一致状态启动并离开系统 处于一致状态。
- 隔离 − 事务的中间结果在当前事务之外不可见。
- 持久性 − 一旦事务被提交,其影响是持久的,甚至 在系统故障后。
Python DB API 2.0 提供了两种提交或回滚事务的方法。
例您已经知道如何实现交易。这是一个类似的示例 -
COMMIT 操作
Commit 是一个操作,它向数据库发出绿色信号以完成更改,并且在此操作之后,无法恢复任何更改。
下面是一个调用 commit 方法的简单示例。
ROLLBACK 操作
如果您对一个或多个更改不满意,并且想要完全还原这些更改,请使用 rollback() 方法。
下面是调用 rollback() 方法的简单示例。
PyMySQL 模块
PyMySQL 是一个用于从 Python 连接到 MySQL 数据库服务器的接口。它实现了 Python 数据库 API v2.0,并包含一个纯 Python MySQL 客户端库。PyMySQL 的目标是成为 MySQLdb 的直接替代品。
安装 PyMySQL
在继续之前,请确保您的机器上已安装 PyMySQL。只需在 Python 脚本中键入以下内容并执行它 -
如果它产生以下结果,则表示未安装 MySQLdb 模块 -
File "test.py", line 3, in <module>
Import PyMySQL
ImportError: No module named PyMySQL
最后一个稳定版本在 PyPI 上可用,可以使用 pip 安装 -
注意 − 确保您具有安装上述模块的 root 权限。
MySQL 数据库连接
在连接到 MySQL 数据库之前,请确保以下几点 -
- 您已创建数据库 TESTDB。
- 您已经在 TESTDB 中创建了一个表 EMPLOYEE。
- 此表包含字段 FIRST_NAME、LAST_NAME、AGE、和 INCOME。
- 用户 ID “testuser” 和密码 “test123” 设置为访问 TESTDB。
- Python 模块 PyMySQL 已正确安装在您的计算机上。
- 您已经阅读了 MySQL 教程以了解 MySQL 基础知识。
要在前面的示例中使用 MySQL 数据库而不是 SQLite 数据库,我们需要更改 connect() 函数,如下所示 -
除了此更改之外,每个数据库操作都可以毫无困难地执行。
处理错误
错误来源有很多。一些示例包括已执行的 SQL 语句中的语法错误、连接失败或为已取消或已完成的语句句柄调用 fetch 方法。
DB API 定义了每个数据库模块中必须存在的许多错误。下表列出了这些异常。
| 异常 | 描述 |
|---|---|
| Warning | 用于非致命问题。必须子类 StandardError。 |
| Error | 错误的基类。必须子类 StandardError。 |
| InterfaceError | 用于 database 模块中的错误,而不是 database 本身。必须子类 Error 的 Error。 |
| DatabaseError | 用于数据库中的错误。必须子类 Error 的 Error。 |
| DataError | 引用数据中的错误的 DatabaseError 的子类。 |
| OperationalError | DatabaseError 的子类,该子类引用错误,例如丢失与数据库的连接。这些错误通常不受 Python 脚本程序的控制。 |
| IntegrityError | DatabaseError 的子类,用于会损害关系完整性的情况,例如唯一性约束或外键。 |
| InternalError | DatabaseError 的子类,该子类引用数据库模块内部的错误,例如游标不再处于活动状态。 |
| ProgrammingError | DatabaseError 的子类,它引用错误,例如错误的表名和其他可以安全地归咎于您的事情。 |
| NotSupportedError | DatabaseError 的子类,该子类引用尝试调用不支持的功能。 |
